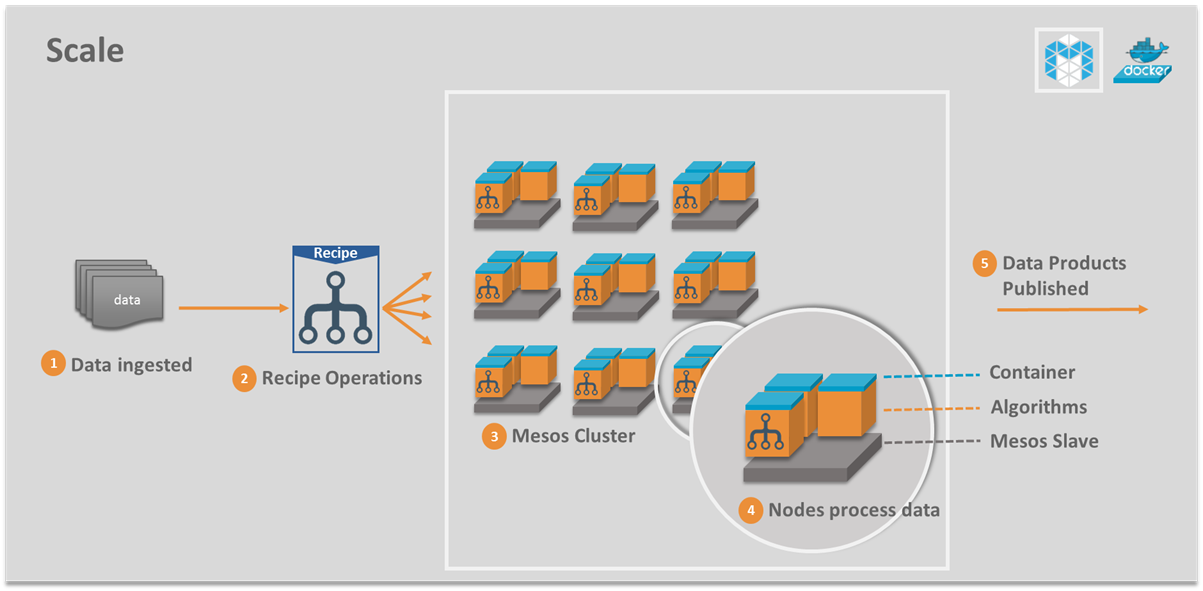
Scale enables on-demand, near real-time, automated processing of large datasets (satellite, medical, audio, video, ...) using a dynamic bank of algorithms. Algorithm execution is seamlessly distributed across thousands of CPU cores. Docker provides algorithm containerization. Apache Mesos enables optimum resource utilization.
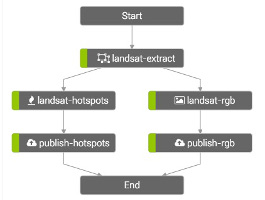
Scale provides the flexibility you need in processing high volume, file-based datasets. It can work with many individual data feeds. Support for custom algorithms and Recipes allows you to implement custom data flows and publish outputs that are accessible via the Scale web UI or REST API.
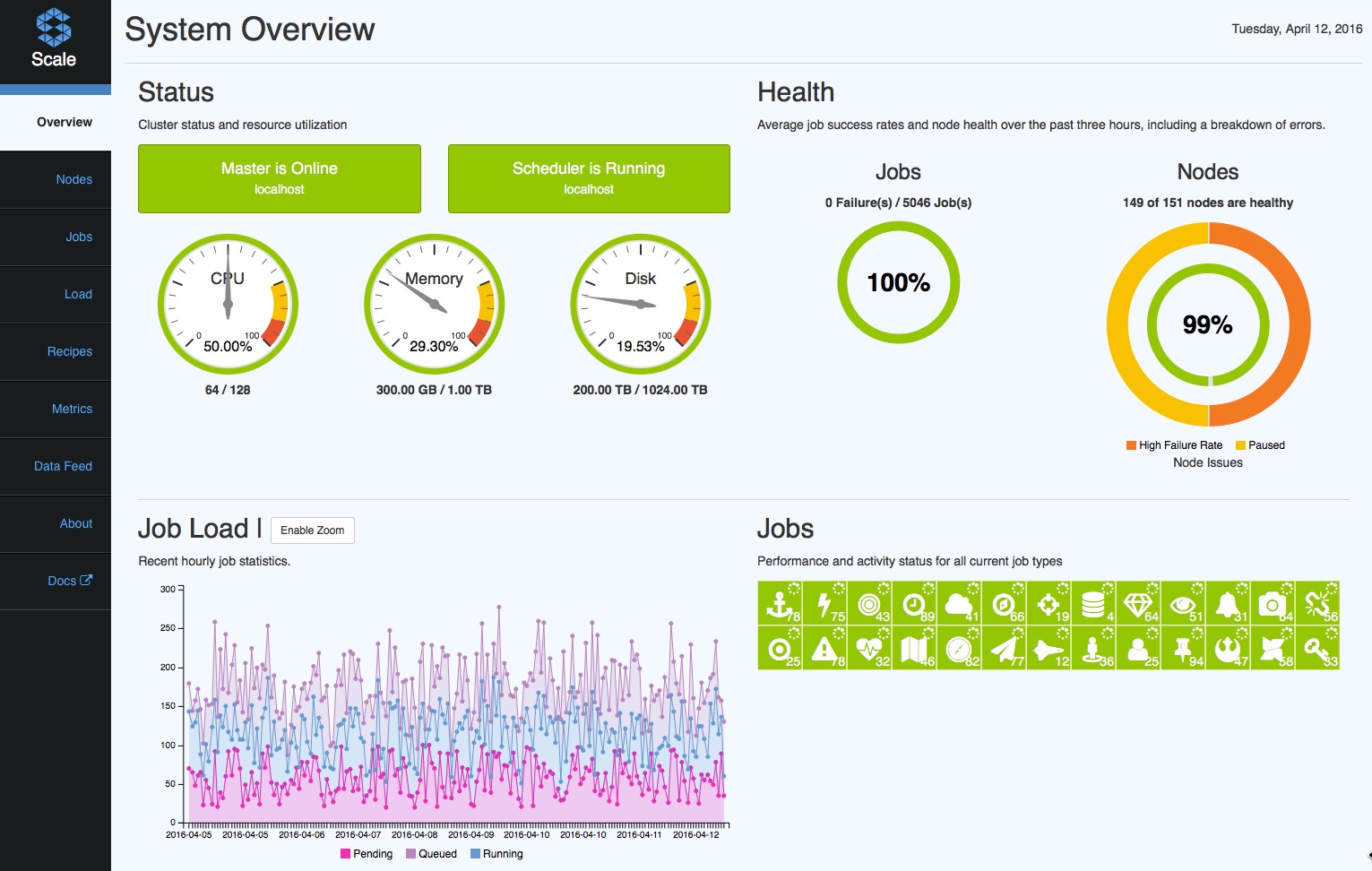
Scale includes a comprehensive web UI that allows you to monitor critical aspects of cluster health and job executions. The UI includes a dashboard that provides important statistics at a glance. Users can access detailed information on Job & Recipe executions, restart failed Jobs, monitor Data Feed status, view processing Metrics and access Products.